Description of Data Mining Methodology Used by the Uppsala Monitoring Centre
| Home | | Pharmacovigilance |Chapter: Pharmacovigilance: Data Mining in Pharmacovigilance
The UMC is, as the WHO Collaborating Centre for International Drug Monitoring, responsible for the technical and scientific maintenance and development of the WHO International Drug Monitoring Programme.
DESCRIPTION OF DATA MINING
METHODOLOGY USED BY THE UPPSALA MONITORING CENTRE
The
UMC is, as the WHO Collaborating Centre for International Drug Monitoring,
responsible for the technical and scientific maintenance and development of
the WHO International Drug Monitoring Programme. The Programme now has 76
member countries, annually contributing around 250 000 suspected adverse drug
reaction (ADR) reports to the WHO database in Uppsala.
One
of the main aims of the international phar-macovigilance programme is to
identify early signals of safety problems related to medicines. To aid this, a
new ADR signalling system has been provided for national monitoring centres and
authorities based on automated exploratory data analysis. It comple-ments the
previous signal detection procedure which involved the examination of unwieldy,
large amounts of sorted and tabulated material by an expert panel. An overview
of the new signalling approach, including results from the first part of an evaluation
including a comparison against another signalling system has been published
(Lindquist et al., 1999).
The
UMC’s main purpose is to find novel drug safety signals: new information. From
experience a principal argument has evolved in drug safety, that, if important
signals shall not be missed, the first analy-sis of information should be free
from prejudice and a priori thinking.
Quantitative filtering of the data focuses
clinical review on the most potentially impor-tant drug adverse reaction
combinations (Bate et al., 1998;
Lindquist et al., 1999, 2000; Orre et al., 2000). Human intelligence and
experience is able to oper-ate better with a transparent filtering method in
the generation of hypotheses.
The
BCPNN is a computational framework based on a statistical neural network where
learning and inference is done using the principles of Bayes law. The network
can take real, discrete and binary vari-ables as input. It is in its most
simple feed forward implementation equivalent to the naïve Bayes clas-sifier,
which is a standard prediction algorithm that has proven efficient in many
applications (Domingos and Pazzani, 1997; Hand and Yu, 2001). The BCPNN can
also be implemented with feedback loops between the input and the output layers
as a form of Hopfield network for unsupervised pattern recognition (Lansner and
Ekeberg, 1989). As such, it has been demon-strated useful in identifying ADR
syndromes based on spontaneous reporting data (Orre et al., 2005). The BCPNN has also been extended to a multilayer network
(Holst, 1997), which has been successfully applied to areas like diagnosis
(Holst and Lansner, 1996), expert systems (Holst and Lansner, 1993) and data
analysis in pulp and paper manufacturing (Orre and Lansner, 1996). Related
research has produced methods to handle uncertainty in Bayes classification
(Norén and Orre, 2005).
The
BCPNN is transparent, in that it is easy to see what has been calculated, and
the results are reproducible, making validation and checking simple. The
network is easy to train; it only takes one pass across the data, which makes
it highly time effi-cient. Because only a small proportion of all possible
drug-adverse reaction combinations are actually non-zero in the database, the
use of sparse matrix meth-ods makes searches through the database quick and
efficient.
The
weights in the BCPNN are referred to as Infor-mation Components (IC). They are
the basis for the data mining method used to screen the WHO database for
unexpectedly strong dependencies between vari-ables (e.g. drugs and adverse
reactions). They can also be used to study how dependencies in the database
change on addition of new data. The IC between drug x and ADR y is defined as
(Bate et al., 1998; Orre et al., 2000):
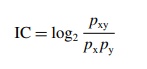
IC
= log2 pxy/pxpy
where
px
= probability of drug x being listed on a case report
py
= probability of ADR y being listed on a case report
pxy
= probability that drug x and ADR y are listed on the same case report.
In
principle, the IC value is based on:
•
the number of case reports with drug x (cx);
•
the number of case reports with ADR y (cy);
•
the number of reports with the specific combination (cxy); and
•
the total number of reports C.
Positive
IC values indicate that the particular combi-nation is reported to the database
more often than what can be expected based on the general reporting of the two
terms in the database. The higher the IC value, the more the combination stands
out from the back-ground. An adjusted IC estimate can also be calculated to
control for possible confounding variables (Norén, Bate and Orre, 2004).
Stratified analyses are part of the routine data mining of the WHO database but
the first pass analysis is unadjusted since it remains unclear how to best use adjustment
in routine data mining (Bate et al.,
2003).
From
the IC probability distribution, expectation and variance values are calculated
using Bayesian statistics. Thus estimates of precision (standard devi-ations)
are provided for each point estimate of the IC, allowing both the point
estimate and the asso-ciated uncertainty to be examined. The interpreta-tion of
the probability distribution is intuitive: the standard deviation for each IC
provides a measure of the robustness of the estimate. The higher the cx,
cy and cxy levels are, the narrower the confi-dence
interval becomes. If a positive IC value increases over time and the confidence
interval narrows, this indicates an increased certainty of a positive
quantitative association between the studied variables.
The
BCPNN framework provides an efficient computational model for the analysis of
large amounts of data and combinations of variables, whether real, discrete or
binary. The efficiency is enhanced by the IC being the weight between nodes in
the neural network. The BCPNN can be used both for data anal-ysis/data mining,
prediction and unsupervised pattern recognition. Bayesian statistics fits
intuitively into the framework of a neural network approach as both build on
the concept of adapting on the basis of new data. The method has also been
extended to detect dependencies between several variables (Orre et al., 2000). Pattern recognition by
the BCPNN does not depend upon any a
priori hypothesis, as an unsu-pervised learning approach is used. This is
useful in new syndrome detection, finding patient age profiles of drug-adverse
reactions, determining at-risk groups and dose relationships; and can thus be
used to find complex dependencies which have not necessarily been considered
before. Naturally, changes in patterns may also be important.
The
automated routine data mining of the WHO database is based on using the BCPNN
to scan incom-ing ADR reports and compare them statistically with what is
already stored in the database. A new quarterly output to national
pharmacovigilance centres contains statistical information from the BCPNN scan.
It also contains frequency counts for each drug and ADR listed, both
individually and occurring together. The figures from the previous quarter are
also included and the data is provided in a computerised format. Drug-adverse
reaction combinations with IC values above a certain threshold are selected for
further consider-ation (‘associations’). As an important complement, a triage
algorithm has been designed to focus atten-tion on the most urgent issues from
an international perspective (Ståhl et al.,
2004) (see Table 21.1, for the fundamental triage algorithm criteria). The case
series thus highlighted by the UMC are forwarded to a panel of clinical
reviewers for evaluation and expert opinion. As previously, signals of possible
safety problems are circulated to all national centres participating in the
international pharmacovigilance programme for consideration of public health
impli-cations. Drug safety issues first highlighted with the UMC’s data mining
system have also been published in the mainstream medical literature (Coulter et al., 2001; Sanz et al., 2005).

Automated
duplicate detection is another important area of application for data mining
methods in phar-macovigilance. The analysis of spontaneous reporting data is
sometimes impaired by poor data quality, and the presence of duplicate case
reports is an especially important data quality problem. Sometimes different
sources provide separate case reports for the same ADR incident and other times
there are mistakes in linking to existing database records any follow-up case
reports submitted to update the original report. With the ultimate aim of
improving data analysis in the WHO database, the UMC has developed a
statistical method for automated duplicate detection in spontaneous reporting
data (Norén, Orre and Bate, 2005). The primary aim is data cleaning, which is
an important component of the knowledge discovery process (Fayyad,
Piatetsky-Shapiro and Smyth, 1996), but duplicate detection can also be
considered as a form of data mining in its own right.
Related Topics
