F Distribution and Applications
| Home | | Advanced Mathematics |Chapter: Biostatistics for the Health Sciences: One-Way Analysis of Variance
The F distribution will be used to evaluate the significance of the association between an independent variable and an outcome variable in an ANOVA.
F DISTRIBUTION AND APPLICATIONS
The F
distribution will be used to evaluate the significance of the association
between an independent variable and an outcome variable in an ANOVA. The F distribution is defined as the
distribution of (Z/n1)/(W/n2), where Z has a chi-square distribution with n1 degrees of freedom, W has a chi-square distribution with n2 degrees of freedom, and Z and W are statistically independent. In the one-way analysis of
variance, Z = Q2/σ2, W = Q1/σ2, n1 = nw, and n2 = nb
– 1; so the ratio [Q2/(nb – 1)]/[Q1/nw] has the central F
distribution with nb – 1
numerator degrees of freedom and nw
denominator degrees of freedom under the null hypothesis. Note that the common
variance σ2 appears in both the numerator and denominator and hence
cancels out of the ratio.
The probability density function for this F distribution has been derived and is
described in statistical texts [see page 246 in Mood, Graybill, and Boes
(1974)].
TABLE 13.1. General One-Way ANOVA Table

The F
distribution depends on the two degrees of freedom parameters n1 and n2, called, respectively, the numerator and denominator
degrees of freedom. We in-clude tables of the central F distribution based on degree of freedom parameters in Appendix A.
A sample ANOVA is presented in Table 13.1.
Although we do not cover the two-way analysis of
variance, Table 13.2 shows the typical two-way ANOVA table that should help you
see how the ANOVA table generalizes to N-way
ANOVAs. Note that as more factors appear, we have more than one F test. This appearance of multiple F tests is analogous to the several F and/or t tests in regression that are used to determine the significance
of the regres-sion coefficients. ANOVA Table 13.2 is not the most general
table. A treatment by block effect also can be considered in the model; in this
case, the table would have another row for the interaction term.
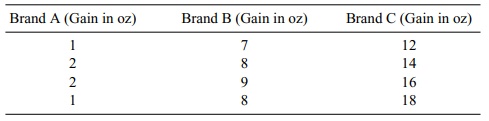
We will illustrate the one-way analysis of variance
with a numerical example. Table 13.3 shows some hypothetical data for the
weight gain of pigs fed with three different brands of cereal. A total of 12
pigs are randomly assigned (4 each) to the three cereal brands.
To generate the ANOVA table, we must calculate SSb and SSw. As a first step in obtaining SSw, we calculate the means for each brand. ![]() A = (1 + 2 + 2 + 1)/4 = 1.5.
A = (1 + 2 + 2 + 1)/4 = 1.5. ![]() B = (7 + 8 + 9 +
8)/4 = 8.
B = (7 + 8 + 9 +
8)/4 = 8. ![]() C = (12
+ 14 + 16 + 18)/4 = 15. The grand mean is X
= (1.5 + 8 + 15)/3 = 8.167. Now SSW
= Q1 = (1 – 1.5)2
+ (2 – 1.5)2 + (2 – 1.5)2 + (1–1.5)2+(7–8)2+(8–8)2+(9–8)2+(8–8)2+(12–15)2+(14–15)2+
(16–15)2+(18–15)2=0.25+0.25+0.25+0.25+1+0+1+0+9+1+1+9=
23. Note that SSw
represents the sum of squared deviations of the individual observa-tions from
their group means.
C = (12
+ 14 + 16 + 18)/4 = 15. The grand mean is X
= (1.5 + 8 + 15)/3 = 8.167. Now SSW
= Q1 = (1 – 1.5)2
+ (2 – 1.5)2 + (2 – 1.5)2 + (1–1.5)2+(7–8)2+(8–8)2+(9–8)2+(8–8)2+(12–15)2+(14–15)2+
(16–15)2+(18–15)2=0.25+0.25+0.25+0.25+1+0+1+0+9+1+1+9=
23. Note that SSw
represents the sum of squared deviations of the individual observa-tions from
their group means.
Now let us compute SSb. We can calculate this directly or calculate SSt and get SSb by the equation SSb = SSt – SSw.
Since SSt is a little
easier to compute, let us do
TABLE 13.2. Typical Two-Way ANOVA Table
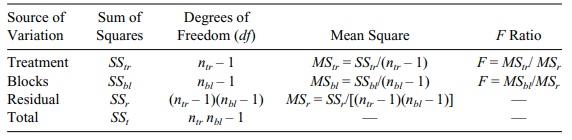
TABLE 13.3. Weight Gain for 12 Pigs Fed with Three Brands of Cereal
We need to get
the overall or “grand” mean—the weighted average of the group means weighted by
their respective sample sizes. In this case, since all three groups have 4 pigs
each, the result is the same as taking the arithmetic average of the three
group averages. So ![]() g
= (1.5 + 8 + 15)/3 = 8.1667. For SSt,
we do the same computations as for SSw
except that instead of subtracting the group means, we subtract the grand mean
before taking the square. So for SSt
we have SSt = Q = (1 – 8.1667)2 + (2 –
8.1667)2 + (2 – 8.1667)2 + (1 – 8.1667)2 + (7
- 8.1667)2 + (8 – 8.1667)2 + (9 – 8.1667)2 +
(8 – 8.1667)2 + (12 – 8.1667)2 + (14 – 8.1667)2
+ (16 – 8.1667)2 + (18 – 8.1667)2 = 51.3616 + 38.0282 +
38.0282 + 51.3616 + 2.7789 + 0.0278 + 0.6944 + 0.0278 + 14.6942 + 34.0274 +
61.3606 + 96.6938 = 391.0845.
g
= (1.5 + 8 + 15)/3 = 8.1667. For SSt,
we do the same computations as for SSw
except that instead of subtracting the group means, we subtract the grand mean
before taking the square. So for SSt
we have SSt = Q = (1 – 8.1667)2 + (2 –
8.1667)2 + (2 – 8.1667)2 + (1 – 8.1667)2 + (7
- 8.1667)2 + (8 – 8.1667)2 + (9 – 8.1667)2 +
(8 – 8.1667)2 + (12 – 8.1667)2 + (14 – 8.1667)2
+ (16 – 8.1667)2 + (18 – 8.1667)2 = 51.3616 + 38.0282 +
38.0282 + 51.3616 + 2.7789 + 0.0278 + 0.6944 + 0.0278 + 14.6942 + 34.0274 +
61.3606 + 96.6938 = 391.0845.
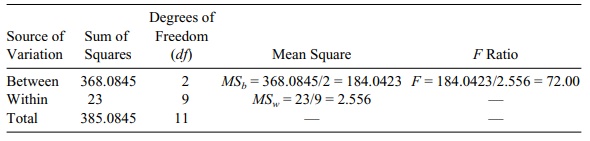
So by subtraction, SSb = 391.0845–23.0 = 368.0845. Now we can fill in the
ANOVA table. Table 13.4 is the ANOVA table of the form of Table 13.1 as applied
to these data.
An F
statistic of 72.00 is highly significant. Compare it to values in the F distri-bution table with 2 degrees of
freedom in the numerator and 9 degrees of freedom in the denominator (Appendix
A). The critical values are 4.26 at the 5% level and 8.02 at the 1% level. So
we see that the p-value is
considerably less than 0.01.
SSb can be calculated directly. The
formula is nob{(![]() A –
A –![]() )2 + (
)2 + (![]() B –
B – ![]() )2 + (
)2 + (![]() C –
C – ![]() )2} = 4{(1.5 – 8.167)2 + (8 – 8.167)2 + (15 – 8.167)2} = 4{44.444
+ 0.0279 + 46.690} = 364.647. This formula applies to balanced designs where nob is the com-mon number of
observations in each group. The difference between the results ob-tained from
the two methods for calculating SSb
(364.667 versus 364.647) is due to rounding errors. Using SAS software and
applying the GLM procedure to these data, we found that SSb = 364.667. So most of the rounding error was in our
calcu-lation of SSt in the
first approach.
)2} = 4{(1.5 – 8.167)2 + (8 – 8.167)2 + (15 – 8.167)2} = 4{44.444
+ 0.0279 + 46.690} = 364.647. This formula applies to balanced designs where nob is the com-mon number of
observations in each group. The difference between the results ob-tained from
the two methods for calculating SSb
(364.667 versus 364.647) is due to rounding errors. Using SAS software and
applying the GLM procedure to these data, we found that SSb = 364.667. So most of the rounding error was in our
calcu-lation of SSt in the
first approach.
TABLE 13.4. One-Way ANOVA Table for Pig Feeding Experiment
Related Topics
